What Is a Standard Essential Patent? Basics and Benefits




As the pace of innovation increases, so does the need for organizations to understand and protect their intellectual property. One type of patent that requires special attention is a standard essential patent (SEP). What is a standard essential patent in technology?
SEPs are unique in that they provide patent holders with rights over technology standards used across multiple industries. To ensure protection from potential infringement, it’s important for R&D managers and engineers to have strategies in place for identifying, managing, and leveraging these patents.
In this blog post, we’ll explore what is a standard essential patent and how to deal with a situation involving SEPs.
Table of Contents
What is a Standard Essential Patent?
How to Identify Potential Standard Essential Patents
Analyzing Existing Patents and Prior Art
Utilizing Technology-Specific Resources
Strategies for Protecting Standard Essential Patents
Establishing Reasonable Royalty Rates
Challenges of Managing Standard Essential Patents
How Can Cypris Help Manage Standard Essential Patents?
What is a Standard Essential Patent?
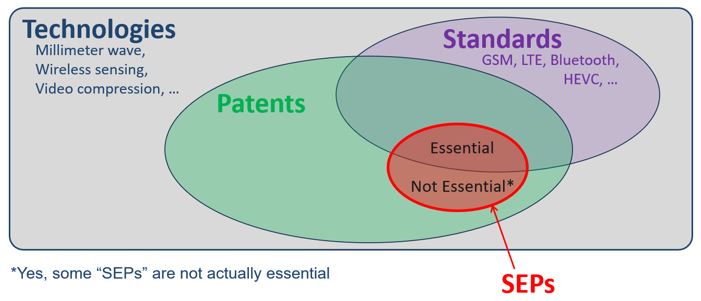
A standard essential patent (SEP) is a type of intellectual property right that covers technology that is essential to the implementation of an industry standard.
SEPs are typically granted by government patent offices and provide the holder with exclusive rights to use, manufacture, or sell products that incorporate patented technology.
Obtaining SEPs can bring several benefits for businesses including increased market share, higher profits, and protection from competitors.
In order to obtain a SEP, certain criteria must be met related to novelty, non-obviousness, and utility.
Novelty requires that the invention has not been previously disclosed in any form before it was filed as a patent application.
Non-obviousness means that someone skilled in the relevant field would not consider the invention obvious.
Utility implies that there is some practical purpose for which it can be used.
The process of obtaining a SEP begins with researching existing patents and prior art as well as analyzing industry standards. Technology-specific resources such as journals or databases may also prove useful when conducting research on potential inventions or innovations covered by a SEP.
Don’t let your invention get lost in the crowd! Get a Standard Essential Patent (SEP) and protect it from competitors. #innovation #patents Click to Tweet
How to Identify Potential Standard Essential Patents
Obtaining a SEP can provide a competitive advantage, but identifying potential SEPs requires research and analysis.
Researching the Market
The first step in identifying potential standard essential patents is researching the market and industry standards. This involves understanding which technologies are necessary for implementing industry standards, such as 5G or Wi-Fi 6, as well as any associated specifications or protocols.
By analyzing these requirements, it’s possible to identify which technologies may be covered by a SEP.
Analyzing Existing Patents and Prior Art
Once potential technologies have been identified, it’s important to analyze existing patents and prior art to determine whether any have already been granted for those technologies. It’s also important to consider how recently the patent was filed since more recent filings may indicate a higher likelihood of being declared essential if challenged in court or arbitration proceedings.
Utilizing Technology-Specific Resources
Patent databases can also be used to search for relevant patents or applications that might cover technology required by industry standards. For example, searching through USPTO records could reveal existing patent applications that relate directly to a specific technology requirement of an established standard. Some databases also offer tools specifically designed for finding SEPs based on certain criteria such as geographic regions or keyword searches within patent descriptions.
Key Takeaway: Researching markets and industry standards, analyzing existing patents, and utilizing technology-specific resources can effectively identify potential standard essential patents that will help companies maintain their competitive edge in today’s rapidly changing world of innovation.
Strategies for Protecting Standard Essential Patents
Protecting standard essential patents is a key part of any R&D team’s strategy. Securing licensing agreements, establishing royalty rates, and filing defensive publications to prevent infringement claims are all important steps in protecting intellectual property rights.
Securing Licensing Agreements
A licensing agreement allows two parties to share patented technology while still maintaining control over it. Companies can enter into these agreements voluntarily or through court orders if necessary. The terms of the agreement should be negotiated carefully as they will determine how much each party benefits from the arrangement.
Establishing Reasonable Royalty Rates
Establishing reasonable royalty rates is an important step in ensuring that both parties benefit from the license agreement without one side being taken advantage of. It is also important to consider potential future changes in industry standards when setting these rates so that they remain fair and equitable over time.
Filing Defensive Publications
Filing defensive publications prevents other companies from claiming infringement on a company’s patented technology in court by providing evidence that the patent was already known prior to these claims. This helps protect against frivolous lawsuits and provides additional protection for valuable intellectual property assets.
Managing standard essential patents requires careful consideration of industry standards, regulations, and open innovation practices as well as access to accurate data sources across teams within an organization. This can be difficult without a centralized platform like Cypris which streamlines research processes and accelerates time-to-insights while enhancing collaboration between R&D teams.
(Source)
Challenges of Managing Standard Essential Patents
Managing standard essential patents presents several challenges.
Keeping track of changes in industry standards and regulations is one such challenge. Companies must stay up to date on any new or revised standards that may affect their licensing agreements, royalty rates, or other aspects of their patent management strategy.
Companies must also ensure compliance with FRAND (Fair, Reasonable, and Non-Discriminatory) principles when negotiating licensing agreements with competitors. This ensures fair competition between companies while still protecting the intellectual property rights of each party involved.
Balancing the protection of intellectual property rights with open innovation practices is another challenge associated with managing standard essential patents. Open innovation practices allow companies to benefit from sharing their patented technologies while still protecting their investments in research and development. Companies must strike a balance between these two goals to ensure they are adequately protected without stifling innovation within the industry as a whole.
Finally, companies should consider a platform like Cypris for managing standard essential patents. This platform can help streamline research processes and accelerate time to insights by centralizing data sources. It also enhances collaboration between R&D teams through its intuitive user interface design and powerful analytics capabilities.
Managing standard essential patents? Let Cypris help you strike the perfect balance between protecting your IP and fostering open innovation! #PatentManagement Click to Tweet
How Can Cypris Help Manage Standard Essential Patents?
Managing SEPs requires specialized knowledge and expertise in order to ensure compliance with industry standards and regulations while protecting intellectual property rights.
The Cypris platform provides R&D teams with the tools they need to manage standard essential patents (SEPs). By centralizing data sources into one platform, teams can quickly access all relevant information about a particular patent. This allows them to identify potential SEPs faster and more accurately.
Streamlining research processes also helps accelerate time to insights, allowing teams to move forward with their projects faster. Teams can easily collaborate on developing new products without having to worry about compatibility issues or other technical challenges that may arise from using multiple platforms.
The Cypris platform also helps protect intellectual property rights while still promoting open innovation practices. It enables users to secure licensing agreements with competitors and establish reasonable royalty rates for those agreements in order to ensure fair compensation for any use of patented technology.
Conclusion
What is a standard essential patent and how does it work?
A standard essential patent is an important tool for protecting intellectual property. Identifying potential standard essential patents requires careful research and analysis of the technology landscape. Strategies such as licensing agreements, cross-licensing, or defensive publication can help protect these valuable assets.
Do you want to stay ahead of the competition and protect your innovations? A Standard Essential Patent (SEP) is a powerful tool that can help. With Cypris, research teams have access to all the data sources they need in one platform for rapid time-to-insights.
Get started today with our innovative solutions and take advantage of SEPs to safeguard your R&D investments!


